Прошло уже примено года 3 с момента как мы переделали Roem.ru на wordpress. Как мы это сделали будет описано в этой небольшой заметке.
Преджде всего надо было выбрать систему на которую переходить, и условия были такие что это должна быть дружелюбная прежде всего к редакторам система, и система на суппорт которой ненужно было бы тратить много ресурсов в будущем, система которая уже была на рынке и имела репутацию именно как система для крупных новостных изданий. Так выбор пал на wordpress, это было да и остается разумным коллективным решением.
Под катом немного подробностей о том какие были проблемы и интересная визуализация вконце.
На старом РоемРу был печально известный Bitrix, архитектура, документация, и способы дистрибуции которого вызывают у соврменных разработчиков печальный или ехидный “хмык”, в зависимости от того сталкивались они с этим(печальный) или только слышли от других (ехидный). В этой заметке я не собираюсь ругать Bitrix, так как это он сам прекрасно сделает за себя, лишь оставлю пару занимательных комментариев по поводу его инфраструктуры. Но сначала, немного смешных скриншотов про битрикса:
Вот скриншот официальной страницы его свежей онлайн документации, кстати документация также доступна в формате .CHM (Hello darkness my friend)
Битрикс и Flash

Битрикс и UTF

Битрикс и безопасность

Вообщем битрикс целиком и полностью является наследием дремучих и плохих практик. Из этого сильно страдает PHP комьюнити, нездоровой взгляд на которое, и палец у виска со стороны разработчиков на других языках зачастую является последствием их работы с битриксом, и является естественным ошибочным обобщением.
Структутура БД в Bitrix совершенно не информативная, от названия полей и таблиц до самого их содержания. Предстояло понять что, откуда, куда, и как это импортировать в Wordpress. В процессе этого случилось много интересного, множественные повторения текстов, непонятные статусы, и рубрики, а также неуникальные имена ссылок, со всем этим предстояло разобраться. Первый неприятный момент работы с такой структурой, это таблица b_iblock_element_prop_s42 которая хранит созданные пользователем структуры и значения, выглядит она вот так:
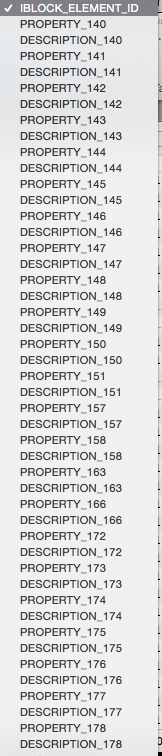
Данные в этих полях были сериализированы и представляли из себя следующее

Все это не просто ужасно, но еще и в cp1251. Кроме этого почти все пользовательские аккаунты в таблице дублировались, то есть были аккаунты с одинаковыми email, к примеру аккаунтов Юры Синдова главреда на тот момент, было аж 5 штук и все они были как я уже писал с одинаковыми emailами, соотвественно при экспорте этих пользователй в Wordpress надо было каким то образом понять какой аккаунт имел смысл а какой нет. Сразу скажу код битрикса мы изучать непытались (хватило и структуры БД)
Посмотрев на все эти “красоты” битрикса, и данные которые нужно перенести я решил это дело автоматизировать. Для этого я написал несколько консольных утилит. Первое что нужно было сделать это перенести структуру статей и рубрик по типам записей.
Проблемы которые возникли в процессе переноса данных
- Связь данных разных сущностей через одну ненормальную таблицу c свойствами где каждое динамическое свойство созданное пользтвателем задается новым полем, в результате все как на скриншоте выше.
- Все данные в базе были в CP1251, а это значит их нужно было конвертировать в UTF
- Неуникальные slugs, что приводило к дополнительной фильтрации уникальных статей по другим параметрам
- Лишние пробелы вконце и даже в начале заголовков статей статей
- Непонятные парамтеры с нерепрезентативными названиями для фильтрации актуальный статей котрые были найдены логическом путем (PARAM1 = ‘E’ да это реально в битриксе название поля в базе PARAM1, PARAM2)
- Сериализованные данные которые затрудняли визуальный и логический поиск и анализ данных
В результате чтобы получить один материал по названию в url (slug) со старого Роема на новый был сделан такой SQL запрос.
SELECT bb.*, p42.PROPERTY_142 as news_type, f.SUBDIR, f.FILE_NAME FROM b_iblock_element as bb LEFT JOIN b_iblock_element_prop_s42 as p42 ON p42.iblock_element_id = bb.id LEFT JOIN b_file as f ON f.id = bb.PREVIEW_PICTURE WHERE bb.SHOW_COUNTER_START != '' AND bb.IBLOCK_ID = 42 AND bb.CODE = '%s' ORDER BY SHOW_COUNTER_START DESC
Как видно выбирается не одна запись, а не сколько по скольку slug был неуникален, - пришлось делать сортировку счетчику просмотров, у опубликованного материала он был больше чем у неопубликованного. Да это был единственный параметр в таблице с материалами по которому, можно было отличить что статья опубликована и отличается от черновика, да статус статьи мог еще быть в таблице со свойствами, но искать в этой куче времени небыло.
CREATE TABLE `b_iblock_element` ( `ID` int(11) NOT NULL AUTO_INCREMENT, `TIMESTAMP_X` datetime DEFAULT NULL, `MODIFIED_BY` int(18) DEFAULT NULL, `DATE_CREATE` datetime DEFAULT NULL, `CREATED_BY` int(18) DEFAULT NULL, `IBLOCK_ID` int(11) NOT NULL DEFAULT '0', `IBLOCK_SECTION_ID` int(11) DEFAULT NULL, `ACTIVE` char(1) NOT NULL DEFAULT 'Y', `ACTIVE_FROM` datetime DEFAULT NULL, `ACTIVE_TO` datetime DEFAULT NULL, `SORT` int(11) NOT NULL DEFAULT '500', `NAME` varchar(255) NOT NULL, `PREVIEW_PICTURE` int(18) DEFAULT NULL, `PREVIEW_TEXT` text, `PREVIEW_TEXT_TYPE` varchar(4) NOT NULL DEFAULT 'text', `DETAIL_PICTURE` int(18) DEFAULT NULL, `DETAIL_TEXT` longtext, `DETAIL_TEXT_TYPE` varchar(4) NOT NULL DEFAULT 'text', `SEARCHABLE_CONTENT` text, `WF_STATUS_ID` int(18) DEFAULT '1', `WF_PARENT_ELEMENT_ID` int(11) DEFAULT NULL, `WF_NEW` char(1) DEFAULT NULL, `WF_LOCKED_BY` int(18) DEFAULT NULL, `WF_DATE_LOCK` datetime DEFAULT NULL, `WF_COMMENTS` text, `IN_SECTIONS` char(1) NOT NULL DEFAULT 'N', `XML_ID` varchar(255) DEFAULT NULL, `CODE` varchar(255) DEFAULT NULL, `TMP_ID` varchar(40) DEFAULT NULL, `WF_LAST_HISTORY_ID` int(11) DEFAULT NULL, `SHOW_COUNTER` int(18) DEFAULT NULL, `SHOW_COUNTER_START` datetime DEFAULT NULL, `TAGS` varchar(255) DEFAULT NULL, PRIMARY KEY (`ID`), KEY `ix_iblock_element_1` (`IBLOCK_ID`,`IBLOCK_SECTION_ID`), KEY `ix_iblock_element_4` (`IBLOCK_ID`,`XML_ID`,`WF_PARENT_ELEMENT_ID`), KEY `ix_iblock_element_3` (`WF_PARENT_ELEMENT_ID`), KEY `ix_code` (`CODE`), KEY `ix_iblock_element_code` (`IBLOCK_ID`,`CODE`), KEY `idx_name` (`NAME`), KEY `idx_name_date_id` (`DATE_CREATE`,`NAME`) ) ENGINE=InnoDB AUTO_INCREMENT=114492 DEFAULT CHARSET=cp1251
Отдельно стоит упомянуть комментарии, дело в том что ссылка на обьект комментирования хранилась также в “чудесной” таблице со свойствами, поэтому предстояло отыскать некое PROPERTY_157 которые указывает на статью.
SELECT u.EMAIL, news.NAME AS news_title, m.TOPIC_ID AS TID, m.* FROM b_forum_message AS m LEFT JOIN b_iblock_element_prop_s42 AS p ON p.PROPERTY_157 = m.TOPIC_ID LEFT JOIN b_user AS u ON u.ID = m.AUTHOR_ID INNER JOIN b_iblock_element AS news ON news.ID = p.IBLOCK_ELEMENT_ID AND news.ID IN ( SELECT e.ID FROM b_iblock_element AS e WHERE e.SHOW_COUNTER_START IS NOT NULL AND e.CODE = '%s' ORDER BY e.DATE_CREATE DESC ) AND (m.PARAM1 IS NULL || m.PARAM1 = 'E' ) GROUP BY m.ID
Пример глупостей которые приходилось делать чтобы выяснить за что отвечают поля со странными названиями вроде PARAM2
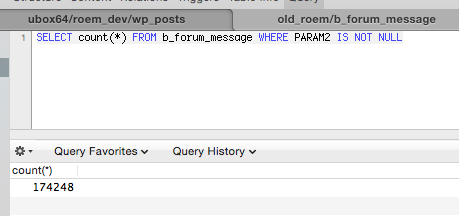
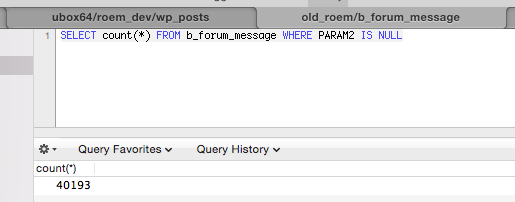
После этого нужно было оформить это все так чтобы можно было запускать это в любой момент времени, и это нерушило бы то что уже перненесено, что и было сделано. Последний шаг это сгенерировать редиректы в виде конфига nginx Код метода который генерит этот конфиг.
public function generateRedirectStringByPostId($post_id)
{
$post = get_post($post_id);
$sql = sprintf("SELECT TRIM(a.NAME) AS title,a.CODE, a.ID
FROM b_iblock_element AS a WHERE TRIM(a.NAME) LIKE '%s'
AND a.SHOW_COUNTER_START IS NOT NULL
AND a.DATE_CREATE = '%s' ", addslashes($post->post_title), $post->post_date);
$st = $this->dbh->prepare($sql);
$st->execute([]);
$data = $st->fetchAll();
if (count($data) == 1 || count($data) == 2) {
$new_link = sprintf('%s/%s', date('d-m-Y', strtotime($post->post_date)), $post->post_name);
if ($data[0]['CODE'] == '') {
$data[0]['CODE'] = 'addednews'.$data[0]['ID'];
}
$rule = sprintf("rewrite /%s/%s/ /%s/ permanent;\n", date('Y/m/d', strtotime($post->post_date)), $data[0]['CODE'], $new_link);
$this->log();
$this->log($rule);
}
}
Как видно всплыла еще одна проблема, некоторые заголовки статей в базе битрикса как оказалось имели пробелы, в результате не все ссылки попадли в конфиг, проблем легко решалась, но трудное диагностировалась. После этого просто генерился прямо на экран конфиг для nginx, записей естественно было много поэтому вывод с консольный утилиты просто перенапрвлялся сразу в конфигурационный файл который потом подключался в nginx. В результате этого конфига все статьи были доступны пользователям через поиск, и при переходе на старый URL пользователь получал старый материал по новому URL.
Мы все тщательно прогоняли на тестовом сервере с тестовой базой, в том числе и редиректы, поэтому у нас было минимум проблем в процессе переключения на новый движок. В процессе реализации старого функционала Роема на новом движке(Wordpress) мы написали кучу плагинов и даже сделали свои мини MVC фреймворк внутри wordpress, который умеет запускаться из консоли, все скрипты по миграции были перенесены в один контроллер в виде методов, и их можно было удобно вызывать уже в продакшен режиме из консоли. Внутри этих методов для миграции данных, я по максимуму использовал API Wordpress Codex, это позволяет избавиться от многих рутиных операций которые уже реализованы в функциях WP (тримирование пробелов в тайталах, форматирование тело статей, и много другого). Что касатеся frontend’a, то там мы использовали CoffeeScript и Gulp который позволил собирать проект и сжимать css, javascript и изображения так, как нам надо, без использования ужасных 3rd party плагинов для WP. Для автоматизированного деплоймента использовался Captistrano, поэтому в случае чего могли быстро окатываться на предъидущий релиз.
Стек в итоге получился такой:
- ubuntu
- nginx
- wordpress
- php 5 в качестве application server был php-fpm
- mysql percona-server
- gulp, coffee, ruby, sass, capistrano
- Mandrill для отправки писем
На этом пожалуй все, но надо сказать что после запуска мы обнаружили некоторые проблемы с перенесенными данными, например обнаружилось что мы удалили все embedded вставки, но благодря тому что код миграционные утилиты можно было удобно переиспользовать из консоли, то возникшие проблемы с данными решились без единого дополнительного SQL запроса. Поправи вырезку embedded вставок, и перезапустив процесс миграции прямо уже на рабочем сайте, зная что это не будет мешать работоспособности.
Задача решена, и надо подвести итоги:
- Даже плохие системы имеют структуру
- Даже плохая структура это структура
- Даже плохую структуру можно конвертировать в хорошую
- Пишите консольные утилиты, и пишите код который можно будет запускать несколько раз даже если вам кажется что будуте запускать его только 1 раз.
- Всегда работайте с копией данных.
- Даже если вы находится в окружении которое вам ненравится, например bitrix или даже php, то стараться сделать задачу правильно нужно все равно, а главное это возможно.
- “Использовать типовые решения для вашего уникального проекта” …. ну вы поняли ? - Любое типовое решение перестает быть им, как только вы начинаете реализовывать на нем свою уникальную бизнес-логику, поэтому максимально используйте возможности той платформы с который вы работаете, читайте документацию в большинстве случаев в ней будет уже решен ваш вопрос.
- Не ругайте технологии, ругайте продукты.
Первые минуты после переключения на новый сайт.
И напоследок немного визуализации коммитов: